YouTube playbook for newsrooms working in high-skepticism contexts
An operational guide to test what we learned about relational trust, retention, information seeking in crisis, and fact-checking habits

This playbook is written for newsroom teams (journalists, editors, and fact-checkers) who want to use what we learned about trust from Gen Z YouTube users in Iran in day-to-day publishing.
The insights in this operational playbook come from a mixed-methods study in Iran, designed around access constraints and safety. We used Telegram-native tools and combined qualitative interviews with quantitative surveys, including a rapid-response survey during the June 2025 Iran–Israel conflict.
You can read our full report here, which was conducted in collaboration with ASL19/Factnameh, or download as pdf:
The research started in a specific context, but the patterns we found are not specific to Iran. They show up in how people decide what to watch, what to believe, and what feels safe to share when information is contested.
This playbook shares what we found and what we experimented with to work in that setting. Each learning also includes a simple way to test whether the same pattern shows up in your own channel and workflow.
In addition to this playbook, we have a free experiment tracking log in Google sheets that contains 20 different experiments you can try, all related to the findings in our report and playbook. If you try these tests, please get in touch and tell us what you find at hello@gazzetta.xyz.

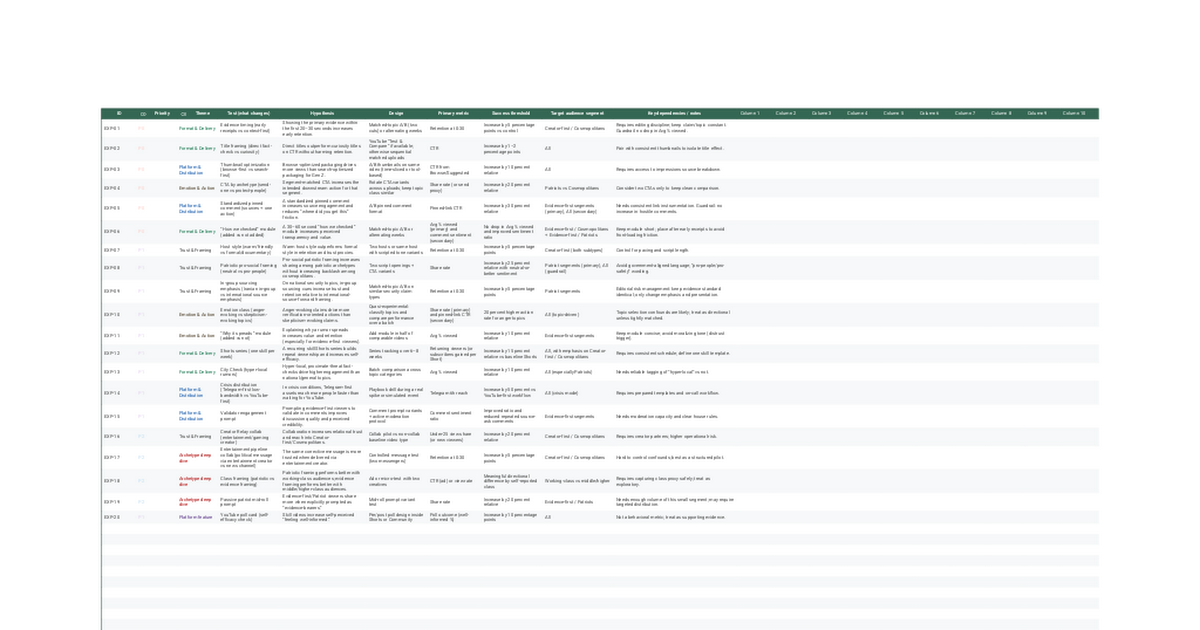
Access our view-only experiment tracking log
Nothing in this playbook is deterministic. Distribution is shaped by many factors outside your control (timing, competition, platform changes, risk, and the wider news cycle), so there is no guarantee of greater reach.
What these moves can help with is making the people you do reach more likely to trust you, return, and share when it feels safe. Over time, that is what builds more stable influence and stronger relationships.
The four learnings below turn the patterns we found into practical moves you can adapt:
- Trust has gates: Win attention first, then earn belief.
- Gen Z is not one audience: Build for segments, not an “average viewer.”
- Crisis compresses the journey: Platforms shift roles, and formats must follow.
- Verification is friction-bound: Make checking a one-step habit.
Each section offers concrete choices you can make in scripting and editing, plus quick tests you can run to check whether a change is helping.
Learning 1. Trust has gates: Win attention first, then earn belief
Where newsroom habits tend to fall short
Many fact-check and debunk formats assume trust is granted upfront, so they open with institutional authority (“we verified this information”) and a lot of proof all at once.
In the Iran YouTube context, that structure often fails to earn the first few seconds of attention from younger viewers who are scanning for immediate relevance, safety, and social fit. The audience leaves before the argument begins, so the work never reaches the people it was designed to persuade.
This is a predictable distribution problem. Rigorous videos can still underperform on watch time and shares. When that happens, they get stuck in a low-reach loop and mostly circulate among already-aligned viewers. Some newsrooms then interpret low reach as an attention problem and respond with more proof, more citations, and a more lecture-like tone, which further raise the cost of engaging.
Over time, the mismatch trains the news team into a defensive posture: If audiences do not accept the "receipts," the newsroom defaults to repeating its verification process and credentials instead of redesigning the sequence of trust. The result is high-effort content that does not reliably translate into understanding, recall, or behavior change (for example, viewers using verification habits on their own).
Why this matters
Trust rarely works like a single “truth test.” It tends to work in steps, like a set of gates.
On YouTube, many Gen Z viewers follow a gating order like this:
- Attention gate: “Is this immediately relevant and legible to me?”
- Safety/relational gate: “Does this feel socially safe, non-scolding, and for someone like me?”
- Evidence gate: “Do I see a clear receipt that justifies belief?”
- Friction gate: “Is verifying (or acting) doable with my time/tools/risk constraints?”
In practice, an opener that leads with method and institutional process often asks for too much too early. It can sound like it is asking the viewer to defer to the newsroom’s authority before the viewer has any reason to do that. Under conditions of high skepticism, surveillance anxiety, and polarized identity dynamics, that can read as scolding or performative, not reassuring.
We also found that attention is not just a metric. Rather, it is the price of entry for someone to understand the rest of the content. If the first seconds fail to establish relevance and rapport, the audience does not reach the "receipts" section at all. So the issue is less about the quality of verification and more about sequencing. Trust cues need to come before the heavy proof, not after it.
How to apply this
Start by deciding what the first seconds need to do. The goal is not "prove we're right." It is to earn enough attention and social safety that the viewer stays long enough to see the receipt.
Open either with the viewer's situation ("If you're seeing X right now...") or with the receipt itself ("Here's the clip/document people are sharing and what it actually shows...").
Then commit to putting one primary receipt on screen quickly, ideally in the first 20–30 seconds. Make it readable. Zoom in. Highlight what matters. Narrate what it’s showing. Hold it long enough for someone watching on a phone to understand.
Keep the tone as a guide, not a referee. The stance is "I checked this so you don't have to," and the logic should fit in one sentence: "People claim X. This receipt shows Y. So X doesn't hold."
Finally, make it easy for someone to believe (and repeat) by giving one small check they can use next time, ideally without leaving YouTube.
Avoid moralizing language (“If you’re a responsible person, you should check…”). Design the check to be doable and socially safe.
Avoid institution-first openers (“We are so-and-so and we verified…”) or a long setup before the first receipt. Do not treat rigor as more words. Long sourcing monologues can function like a paywall for attention.
What success looks like
Success is when more of the intended audience makes it to the receipt and stays long enough to process it. In analytics, you see stronger retention in the first 10–30 seconds and fewer drop-offs right before the evidence appears. In the newsroom, the team spends less time defending credentials and more time refining sequencing, clarity, and tone.
Qualitatively, the comment mix shifts from intent attacks ("who are you?") toward information-seeking and utility ("where is the source?" "this helped," "I can show this to someone"). Saves are a particularly good early signal that the piece is working as private reference material, not just public “dunking.”
What to test
One way to learn is to run a simple A/B pattern over a few similar stories: Publish two versions in sequence, changing only one thing, and compare how people watch them.
Publish two comparable uploads, changing only the first 10 seconds. In upload 1, open situation-first by naming the viewer’s problem and stakes (“If you’re seeing X right now…”). In upload 2, open proof-first by putting one clear receipt on screen and stating the implication in one sentence (“Here’s the one clip/document that matters…”).
UTMs (Urchin Tracking Module) keep track of traffic sources and media by identifying a campaign with UTM parameters in the url.
A sample UTM schema for this experiment is something like this:
- utm_source: youtube / telegram / instagram
- utm_medium: pinned_comment / description / end_screen / post
- utm_campaign: EXP-04_2026_04_topic-slug
- utm_content: variant_A
As an example, for Gazzetta content we could add a UTM parameter to our url like this: http://gazzetta-dot-xyz/ iran-youtube-playbook/utm_source=linkedin
To judge the result, focus on whether the opener clears the early trust gates (attention and social safety). Check retention at 0:10 (did people stick around past the hook?) and retention at 0:30 (did they make it to the proof?). Then scan qualitative and “private utility” signals: comments should move away from intent attacks (people questioning motives, like “propaganda / who are you?”) and toward information-seeking or gratitude (“where is the source,” “thanks,” “I didn’t know”). Saves should rise (people are keeping it for later). If you use a pinned source link, higher clicks can be a supporting signal.
Treat two patterns as warning signs of a false win. If CTR (click-through rate) rises but 0:30 retention drops, the packaging may be pulling people in but not delivering. If retention rises but comment sentiment collapses, tone or framing may be triggering distrust.
Ship the opener that improves retention at both 0:10 and 0:30 (more people stay, and more people reach the proof) without breaking those guardrails (your “don’t make it worse” checks, like trust and tone). Iterate if it improves one metric but not the other. Kill it if it lowers early retention or increases backlash signals.
Access the complete tracking template here.
EXP-01: Testing evidence timing
- Hypothesis: Showing the primary receipt by 0:30 increases retention.
- Design: Matched-topic A/B test: Situation-first/Context vs. Proof-first/Early receipt.
- Metrics and guardrails: Tracking retention at 0:30 without letting average percent viewed drop.
- Success threshold: Increase by 5% versus control.
Key dependencies: Requires editing discipline; keep claim/topic constant.
Where this can go wrong (and how to prevent it)
- Risk: Warm tone reads as unserious for some.
Keep language casual but make the evidence crisp: name the source, show the timestamp, and state the inference clearly.
- Risk: Situation-first feels like clickbait if you delay the proof.
Treat situation-first as a bridge, not a tease, by committing to showing proof within 20–30 seconds.
- Risk: Identity-coded framing triggers distrust (“sounds like state media,” or “sounds like diaspora propaganda”).
Use “pro-people / pro-safety” framing; avoid scolding, triumphalism, or partisan signaling; explicitly separate facts from uncertainty.
Learning 2. Gen Z is not one audience: build for segments, not an “average viewer”
Where newsroom habits tend to fall short
Many newsrooms treat “Gen Z” as a single persona and build one editorial package around it: one presenter archetype, one pacing, one tone, one set of credibility cues, and one call to action. The Iran YouTube findings point to the opposite reality. Young audiences split across different trust anchors and identity filters, so a single package often performs unevenly. When a format works for one subgroup, it can signal “not for me” to another.
That tends to create two problems at once. First, teams misread what’s working because the big, overall numbers hide tradeoffs between different audience groups. A creative choice that increases reach can reduce perceived credibility for another cluster, or vice versa. Second, decision-making gets shaky because each new upload seems to contradict the last. Teams get whiplash changes and "style" debates instead of clear audience hypotheses.
The result is wasted iteration cycles and fragile audience relationships. Instead of building repeatable pathways for different viewer types, teams keep trying to force convergence into one voice. In constrained information environments, where people rely heavily on social proof and identity cues, that one-size strategy can increase skepticism and reduce willingness to share.
Why this matters
We saw different “trust anchors” that shaped what people considered credible in the first place (for example, trusting a familiar creator voice vs. trusting clear sourcing shown on screen). For some viewers, credibility was relational and creator-mediated: a familiar voice, shared cultural cues, and a sense of "this person gets it" carried more weight than formal proof structures. For others, credibility was procedural: citations, demonstrations, and transparent sourcing mattered most, and creator-style presentation could even reduce perceived seriousness.
Identity cues often acted like a filter before people even evaluated the content. Presenter persona, language register, and even the implied community around a channel influenced whether a viewer felt the video was intended for them, safe for them, or aligned with their values. That meant two audiences could watch the same claim and walk away with different judgments because they were responding to different cues, not just different facts.
Newsrooms tend to collapse these differences because segment-level patterns do not show up cleanly in aggregate analytics. The result is a repeated mistake: optimizing for "average Gen Z" and then being surprised when a format that boosts one segment depresses another. What looked like inconsistent performance was often predictable once we treated the audience as multiple pathways with different trust entry points.
How to apply this
Start by choosing a target segment on purpose, before anyone writes a script. The key question is not “what would Gen Z like.” It is which trust entry you are designing for: a creator-first, relational entry, or an evidence-first, procedural entry. If the topic is identity-sensitive, decide whether you need neutral framing or pro-people/pro-safety framing.
Once you have picked the target, hold the receipts and verdict constant and change only the wrapper. In practice, vary the hook, tone, pacing, and call to action. Do not vary what the evidence shows or what conclusion you draw. Use the table below as a translation layer. It is the same content delivered through two credibility styles.
| Creator-first wrapper | Evidence-first wrapper |
|---|---|
| Hook is situational and conversational | |
| (“If you’re seeing X…”). | Hook is claim + verdict immediately. |
| Host tone: warm, fast, non-scolding. | Host tone: neutral, precise, low-drama. |
| Proof appears early (by 0:20–0:30), but explanation is in plain language. | Proof is shown early and clearly; then a brief “how we checked.” |
| Call to action defaults to micro-actions: save / send to one person. | Call to action defaults to validation: source click / replicate the check. |
If you decide to use identity framing, treat it as a safety choice, not a patriotic or partisan signal. Use community-protection language, avoid government-coded symbols and scolding, and separate “people/country” from “state/government” explicitly when needed.
What success looks like
Success is when you stop arguing about “Gen Z taste” in the abstract and start running stable, repeatable pathways for different segments. In practice, creator-first and evidence-first versions can both succeed without one cancelling out the other, because each is judged against the right success signals.
You should see clearer metric patterns: creator-first versions win on early retention and saves (relational entry and private utility), while evidence-first versions win on average percent viewed and source behavior (clicks, fewer repeated “source?” requests). Over time, success is also operational: fewer whiplash format changes, fewer internal debates framed as style, and more deliberate choices tied to a target audience hypothesis.
What to test
Test two different “wrappers” on similar uploads. Pick a short run of stories on the same kind of topic. Keep the receipts and verdict consistent, but change only the wrapper each time you publish. In upload 1, use creator-first packaging: a situational, conversational hook and a warm, fast, non-scolding host tone. In upload 2, use evidence-first packaging: a claim plus verdict immediately, a neutral and precise tone, and a brief “how we checked.”
Then evaluate each track against the success signal that matches its trust entry point. For creator-first, look primarily at early retention (0:10 and 0:30) and saves per 1,000 views (are people keeping it to use or share later?). For evidence-first, look at pinned-source link CTR (click-through rate, if you use one), average percent viewed (how much of the video people watched), and how often commenters ask for sources. Ideally, requests for sources fall because the sourcing is already legible.
Beware of optimizing into distrust! If sentiment collapses, if intent attacks spike (“propaganda / biased / who are you”), or if CTR rises while early retention drops, result is probably more a packaging problem rather than a content win.
Don’t pick a single global winner after one pair. To avoid “one story” skewing the result, run the test over four similar uploads: A, then B, then A again, then B again. After that, keep both formats if each one performs best on its own target metrics and neither triggers the guardrails.
Access the complete tracking template here.
EXP-07: Testing host style
- Hypothesis: Warm host style outperforms formal style in retention and trust proxies.
- Design: Two hosts or same host with scripted tone variants.
- Primary metric: Retention at 0:30.
- Success threshold: Increase by 5%.
- Key dependencies: Control for pacing and script length.
Where this can go wrong (and how to prevent it)
- Risk: segmentation becomes “two channels in one channel” and confuses viewers.
Standardize branding and verification rigor; vary only the entry style. Use recurring series names so audiences know what they’re getting.
- Risk: creator-first wrapper is perceived as unserious or entertainment-coded.
Keep receipts highly visible and specific; avoid sarcasm; state the claim/verdict clearly.
- Risk: evidence-first wrapper feels cold, moralizing, or institution-first.
Keep the tone non-scolding; move “we verified” language later; make the method legible but not self-congratulatory.
- Risk: identity framing gets misread as government-aligned patriotism.
Use “pro-people/pro-safety/pro-community” language; avoid state symbols and government-coded phrasing; explicitly separate “country/people” from “government.”
- Risk: analytics can’t cleanly show segments, leading to wrong conclusions.
Evaluate by proxies (traffic source, retention shape, pinned link CTR, saves) and supplement with small Telegram feedback checks.
Learning 3. Crisis compresses the journey: platforms shift roles, and formats must follow.
Where newsroom habits tend to fall short
In crisis moments, many newsrooms assume the primary problem is accuracy under pressure. So teams double down on verification gates and longer turnaround. In the Iran YouTube context, the audience journey compresses. People want fast, reachable updates, and they choose platforms that minimize friction and maximize social propagation. If a newsroom treats YouTube like a live-update channel, it often arrives late with the wrong content shape for the moment.
That creates a mismatch between what YouTube is best used for in that moment and what the video is trying to do. YouTube becomes more useful for recap, synthesis, and durable explainers once the initial scramble passes. But teams keep pushing incremental updates that do not match audience urgency or the platform's distribution dynamics. Teams then experience "algorithm hostility" when the real issue is timing and format alignment.
The operational consequence is that high-stakes attention is lost early, and later content has to fight uphill against narratives that have already hardened elsewhere. By the time a careful YouTube video lands, the audience may be seeking closure, identity affirmation, or community cues rather than a late evidentiary reconstruction. Newsrooms end up feeling like they are "behind" even when they are doing the work correctly, because they optimized for the wrong phase of the crisis journey.
Why this matters
Crisis compresses the decision window and changes platform roles. When stakes rise, audiences do not patiently move through a multi-step verification journey. They do this instead:
- They prioritize reachability: whichever channel loads, forwards easily, and is already inside their social graph wins.
- They use faster shortcuts: social forwarding, perceived proximity, and familiar voices matter more because time is short and uncertainty is high.
- They shift YouTube’s job: YouTube is used less as “updates” and more as:
- a synthesis layer (what happened, what’s confirmed, what’s false)
- an archive/reference (something to revisit or send later)
- a proof container (durable receipts, explainers)
Newsroom workflows, however, often stayed locked into one publishing rhythm. That can create a mismatch between how fast you publish and what the audience needs in that phase. The problem was not that YouTube cannot carry urgent information; it was that the audience was using it differently at different moments, and newsroom formats did not adapt to those phase changes.
How to apply this
When a story enters “crisis mode,” the main shift is not that you become less rigorous. It is that the audience’s decision window shrinks, rumors move faster, and platforms take on different jobs. Treat this as an editorial mode change.
First, label the story internally as Crisis Mode when stakes, uncertainty, and rumor velocity are high. Once you do, switch the goal from “tell the full narrative” to “reduce confusion without creating new risk.”
On YouTube, prioritize synthesis rather than minute-by-minute updates. Lead with what you know, what you do not know yet, and what is false, with timestamps. Keep the format tight and put a visible receipt on screen early (around 0:20–0:30). Use disciplined uncertainty language (“confirmed,” “unconfirmed,” “cannot verify yet”) so viewers can carry the distinction forward.
To ship fast without improvising every time, standardize a template: use a clear crisis title (“What’s confirmed about [event/claim] (updated [time])”) and a repeatable segment order (claim/situation → what’s confirmed → key receipt → what’s false → what to watch next → one-step check and sources). Close with a crisis-appropriate call to action that defaults to low-risk micro-actions (“Save this” or “Send to one person who’s worried”), rather than “share widely.”
What success looks like
Success in crisis mode looks like confusion reduction without trust collapse. The piece becomes something people can point to when they are overwhelmed: clear enough to be useful, careful enough to be safe.
In analytics, you see stronger retention at 0:30 (proof arrives early) and stable or improving average percent viewed (people are actually watching the synthesis, not bouncing). In qualitative signals, intent attacks and identity fights do not spike. Instead, you see more information-seeking questions ("can you verify X?") and more gratitude or relief ("this helped"). If you use a pinned source, CTR (click-through rate) holds or rises. That can signal that “show your work” is landing as reassurance rather than self-justification.
What to test
In crisis mode, evaluate content on clarity and trust, not raw views. Pick a fixed comparison window (for example, the first 48 hours after publishing) so you are not comparing apples and oranges.
Start with the core clarity check: does retention at 0:30 (how many people are still watching 30 seconds in) improve versus your baseline (your typical crisis uploads)? If it does, you are probably delivering proof early enough. Then confirm that the synthesis is actually useful by checking that average percent viewed and average view duration are stable or improving.
Next, check trust proxies so you do not optimize into spectacle. If you use a pinned source link, CTR should hold steady or increase. In comments, look for a shift away from identity or intent attacks (“propaganda / who are you?”) and toward information-seeking (“source?” “can you verify X?”) and utility (“thanks / this helped”).
Ship if retention at 0:30 improves and the trust proxies do not worsen. Iterate if retention improves but comments show confusion about what the receipt proves, which usually means the on-screen evidence is not legible enough. Kill or re-edit if CTR is high but retention collapses across 0:10–0:30, which often indicates sensational or unclear packaging.
Access the complete tracking template here.
EXP-14: Testing Telegram-first, low-bandwidth format versus YouTube-first
- Hypothesis: In crisis conditions, Telegram-first assets reach more people faster than waiting for YouTube.
- Design: Playbook drill during a real spike or simulated event.
- Primary metric: Telegram 6h reach.
- Success threshold: Increase by 50% versus YouTube-first workflow.
- Key dependencies: Requires prepared templates and on-call workflow.
Learning 4. Verification is friction-bound, make “checking” a one-step habit.
Where newsroom habits tend to fall short
When audiences do not verify claims or do not accept verification content, many newsrooms interpret it as ideological resistance, low media literacy, or bad faith. In response, teams add more information and tighten the moral framing (“you should check this”), assuming more argument will overcome disbelief. In the Iran YouTube setting, that can backfire because the real constraint is often practical friction, not disagreement.
Verification is often “friction-bound.” It competes with time scarcity, tool access, language barriers, and the social risk of being seen as "doing politics" or "siding" with a camp. If a verification pathway feels slow, technically difficult, or socially costly, viewers will avoid it even when they care about truth. Adding more steps, more context, and more instruction increases mental effort and pushes the behavior further out of reach.
The result is a compounding design failure. The newsroom keeps shipping content that assumes an ideal viewer who has time, bandwidth, and confidence to follow a multi-step evidentiary trail. Meanwhile, the actual audience makes rational tradeoffs under constraint and chooses simpler trust heuristics, such as creator affinity or community consensus. Without redesigning verification as a low-friction, socially safe action, the newsroom cannot convert good information into verified belief.
Why this matters
Non-verification frequently reflected constraint, not ideology. Viewers described verification as costly in multiple ways: it took time they did not have, required tools or skills they did not feel confident using, and sometimes depended on access they could not reliably get (bandwidth, language, blocked services). Under those conditions, "verify it" reads less like empowerment and more like an unrealistic assignment.
Social risk mattered as much as technical friction. In polarized environments, checking or sharing verification steps can signal alignment, invite harassment, or create interpersonal conflict. Even when someone privately cares about accuracy, they may avoid overt verification behaviors because it feels politically legible or socially unsafe.
That is why small design choices had outsized effects. If a verification step reduced time, reduced exposure, or reduced the number of actions required, it became thinkable. When a newsroom added more explanation, more links, or more admonishment, it increased both cognitive load and social visibility. Behavior changed less through argument and more through making the check easier and lower-risk.
How to apply this
Treat verification as something people do under constraint. The practical goal is not to teach every method. It is to make one repeatable checking move feel doable.
In each video, include exactly one “one-step check” that can be done without leaving YouTube, can be taught in about 10 seconds, and is easy to repeat the next time a similar claim shows up. Make the check visual. Put the receipt on screen early, make it legible (zoom, highlight, arrows), and narrate it in one sentence: what it is and what it implies.
If you have additional steps that matter, keep them optional and clearly labeled as “extra” or “for power users.” Do not make advanced tooling the main path. Pre-write one reusable line that acknowledges constraints and gives permission for the minimal action ("If you don't have time to check everything, do just this one thing.").
Finally, make sources discoverable without making people hunt. If links are safe and stable, use a pinned comment with one link and one sentence describing what is there. If links are risky or frequently blocked, give a search string viewers can copy instead.
What success looks like
Success is when viewers can repeat the check on their own, and the check spreads as a habit rather than as a lecture. You see this when comments start quoting the method back (“pause here,” “look at the date,” “check the boundary of the clip”), not just debating the claim.
In metrics, saves rise because the video becomes a reference people keep. Retention holds (the check did not slow the video or feel like scolding), and you do not see an increase in “this is too complicated” reactions. If you use pinned sources, CTR can rise, but the stronger signal is that the one-step check reduces repeated confusion and reduces “where is the source?” loops by making the evidence legible on-screen.
What to test
Try a simple two-video comparison on similar topics, changing only the verification instruction. In upload 1, teach one in-video check that can be done without leaving YouTube. In upload 2, give a more traditional multi-step instruction that relies on links, search, or switching apps. Keep everything else as consistent as possible (length, host, pacing, topic class, and receipt quality).
Then look for evidence that the instruction is actually becoming usable. Saves per 1,000 views should rise if the video is functioning as private utility. Comments should start repeating the check back in their own words (for example: “Pause at 0:18—the date is from last year.”). If you use a pinned source link, CTR should increase without a corresponding spike in distrust comments.
Use three guardrails to make sure you did not trade clarity for “teaching.” Retention at 0:30 should not drop, comment sentiment should not worsen into lecture backlash, and the rate of “where is the source?” comments should not rise.
Repeat once more (A then B again on the next comparable pair) before you treat the result as a rule. Ship the approach that increases saves and check-repetition while holding retention steady. Iterate if saves rise but people seem confused, which usually means the on-screen cues are not clear enough. Kill it if retention drops or commenters signal that the check is too complicated or not doable.
Access the complete tracking template here.
Consider developing a publishing checklist that includes what to include in content description fields, a standardized pinned comment, video chapters, and other elements. Using this checklist will:
- Make performance comparable across videos. If titles, descriptions, pinned comments, and chapters vary wildly, you can’t tell whether results came from the idea or from inconsistent packaging.
- Prevent avoidable trust loss. Missing sources, unclear descriptions, or inconsistent tone can trigger “distrust” before evidence lands.
- Reduce operational mistakes. Publishing is where teams forget links, variants, or moderation settings—this checklist makes those failures rare.
EXP-05: Testing standardized pinned comments with a source and an action
- Hypothesis: A standardized pinned comment increases source engagement and reduces “where did you get this” friction.
- Design: A/B pinned comment format.
- Primary metric: Pinned-link click-through-rate.
- Success threshold: Increase by 30% relative.
- Key dependencies: Needs consistent link instrumentation.
- Guardrail: no increase in hostile comments.
EXP-06: Testing a “how we checked” module
- Hypothesis: A 30–60 second “how we checked” module increases perceived transparency and value.
- Design: Matched-topic A/B or alternating weeks.Primary metric: Average percentage viewed (primary) and comment sentiment (secondary).
- Success threshold: No drop in average percentage viewed and improved sentiment ratio.
- Key dependencies: Keep module short; place after early receipts to avoid front-loading friction.
Where this can go wrong (and how to prevent it)
- Risk: “One-step checks” oversimplify and create false confidence
Label it explicitly as a first filter, not a full investigation: “This doesn’t prove everything—but it quickly rules out the most common trick.”
- Risk: The receipt is not visually legible (small text, cluttered screenshots)
Enforce a receipt readability rule: zoom, highlight, freeze frame for at least 2–3 seconds, and restate the conclusion in one sentence.
- Risk: Viewers interpret “verification instruction” as condescension or scolding
Remove moralizing language (“you should…”) and use enabling language: “If you want a fast way to check…
- Risk: Safety / social risk increases (viewers feel exposed by sharing)
Default to private actions and neutral wording: “Save this for later” / “Send to one person who asked you about it” rather than “correct people.”
- Risk: Evidence-first viewers feel the content is too lightweight
Keep the one-step check early, then offer an optional “show your work” module: “If you want the full chain, sources are pinned.”
Research note
This playbook draws on a Telegram-native, mixed-methods research design from our Youtube project studying Gen Z in Iran. We combined qualitative interviews with two Telegram surveys, using Telegram-native tools to fit access and safety constraints.
The qualitative work included 7 in-depth interviews and 140 AI-moderated Telegram interviews. The quantitative component included a rapid-response Telegram survey run during the June 2025 Iran–Israel conflict (usable sample: 584) and a later final Telegram survey (usable sample: 2,059).
Recruitment was opt-in, primarily through ASL19’s VPN network and Telegram advertising.
If you have feedback or questions, or want access to our experiment testing log, don’t hesitate to get in touch at hello@gazzetta.xyz.